
로그 수집, 분석 플랫폼 구축과 관련된 두번째 포스팅 이며, AWS Elasticsearch를 구축하는 초기 단계입니다.
Elasticsearch를 이용하는 방법은 다 알다시피 직접 설치하는 방법과, SaaS 서비스를 이용하는 방법이 있겠다.
아래 내역들은 AWS Elasticsearch를 이용하는 방법으로서 이것도 설정하는 것에 따라 조금씩 나눠질 수 있다.
나같은 경우 ES를 VPC내부로 설정하여 생성하였으며, 키바나 접속은 SOCK5 프록시를 통해 접속하고 있다.
SOCK5 프록시 외에도 Cognito를 이용해 접속하는 방법도 있으며 구글링 하면 쉽게 찾을 수 있다.
1. ES가 사용할 SecurityGroup을 미리 하나 만들어 둠. 우선은 HTTPS만 허용 해도 충분 하다.

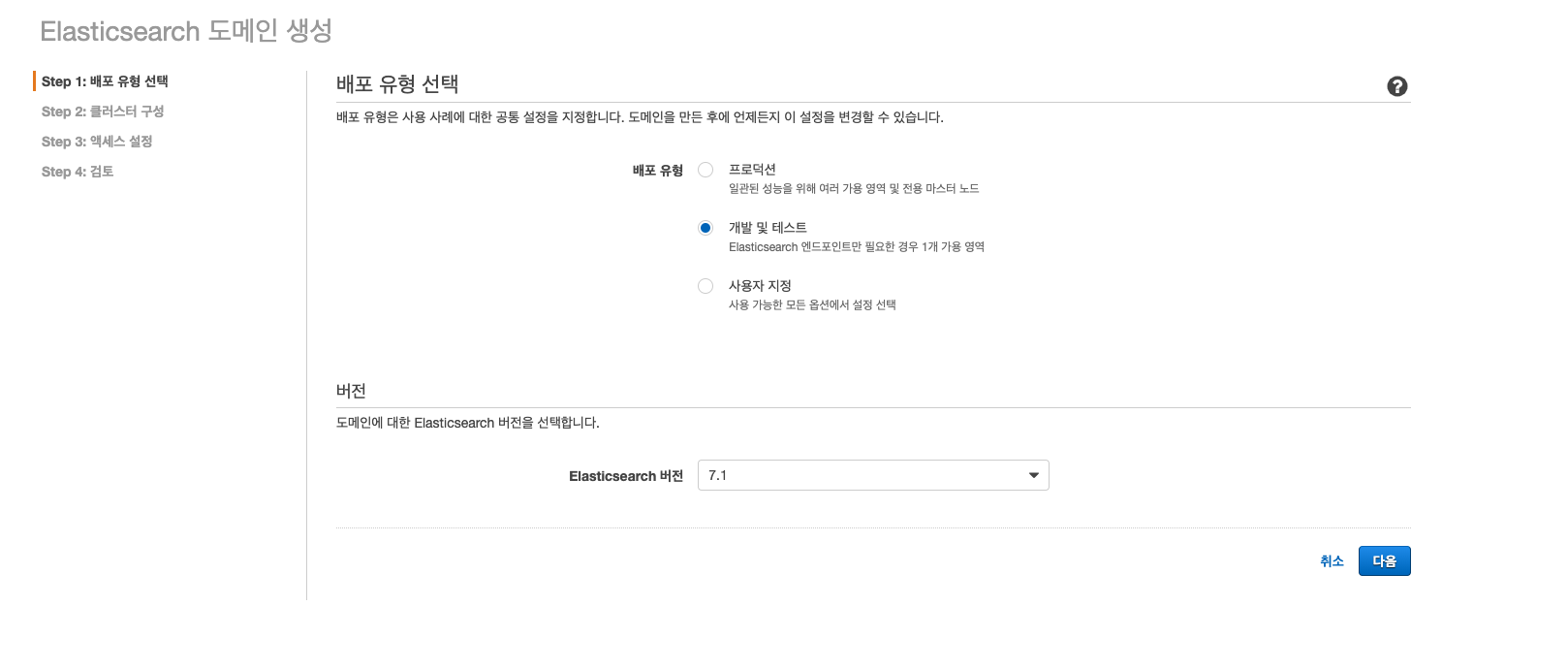
2. 새도메인 생성 버튼을 누른 후 배포 유형과 버전을 선택. 난 7.1을 선택
- 7.1은 아직 Kinesis와 호환이 안되니 Firehose를 같이 쓸 계획이라면 6.x로 선택 하면 됨.
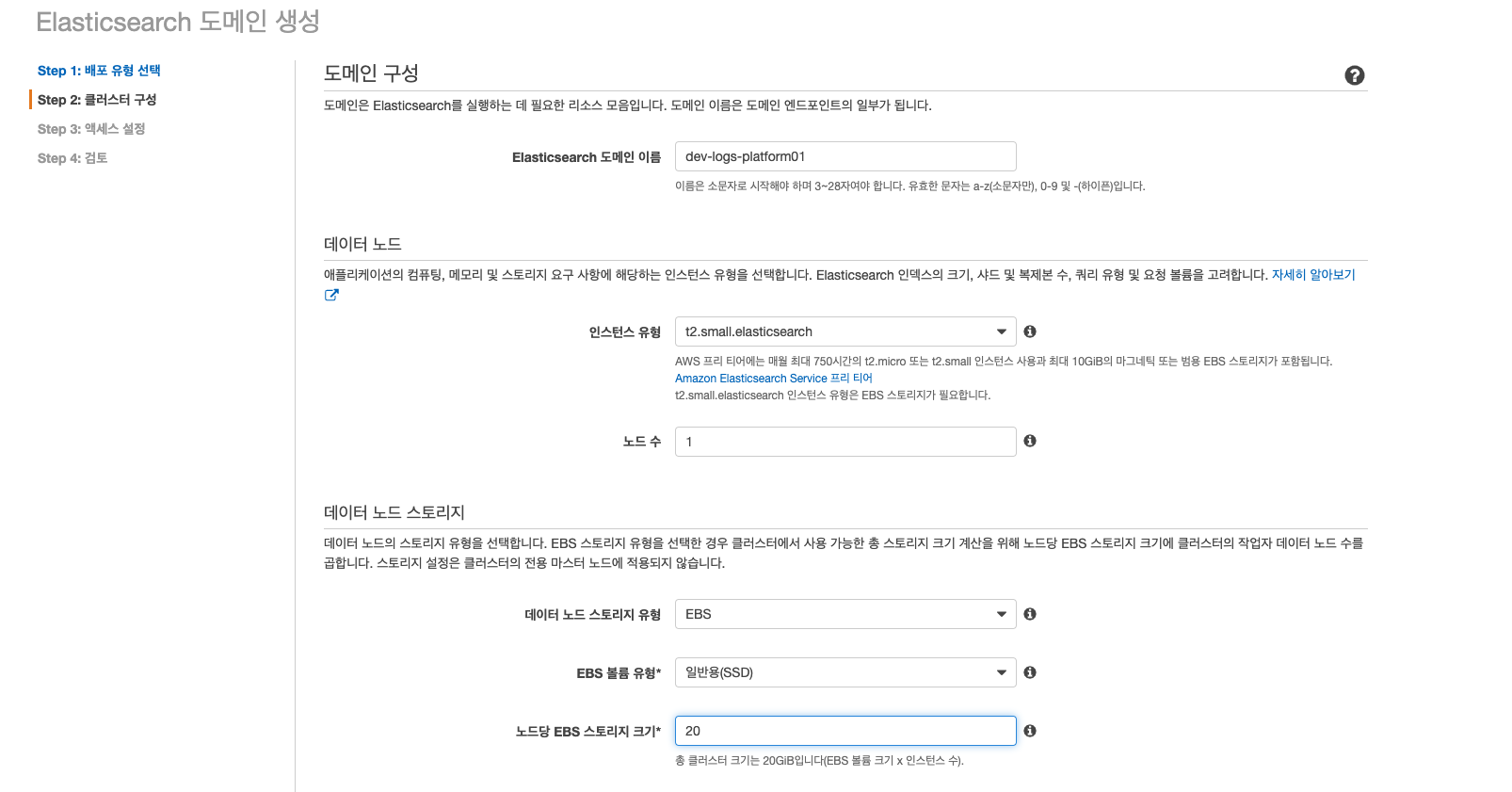
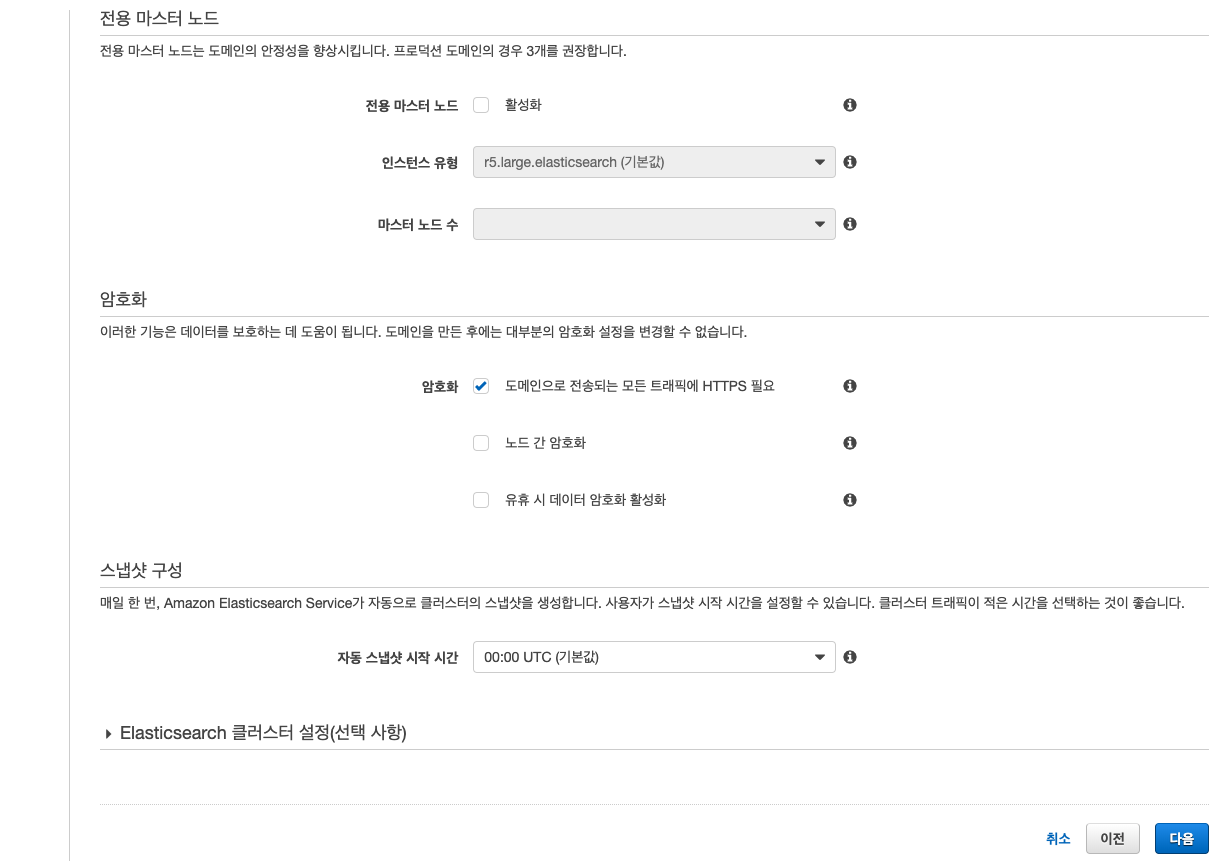
3. ES의 이름과 인스턴스 타입, 데이터노드, 마스터 노드 등을 선택하면 되는데 개발 단계이니 가장 싼걸로…
- 나머지 자잘한 옵션들은 공식 문서를 한번 찾아 보고 결정 하자.
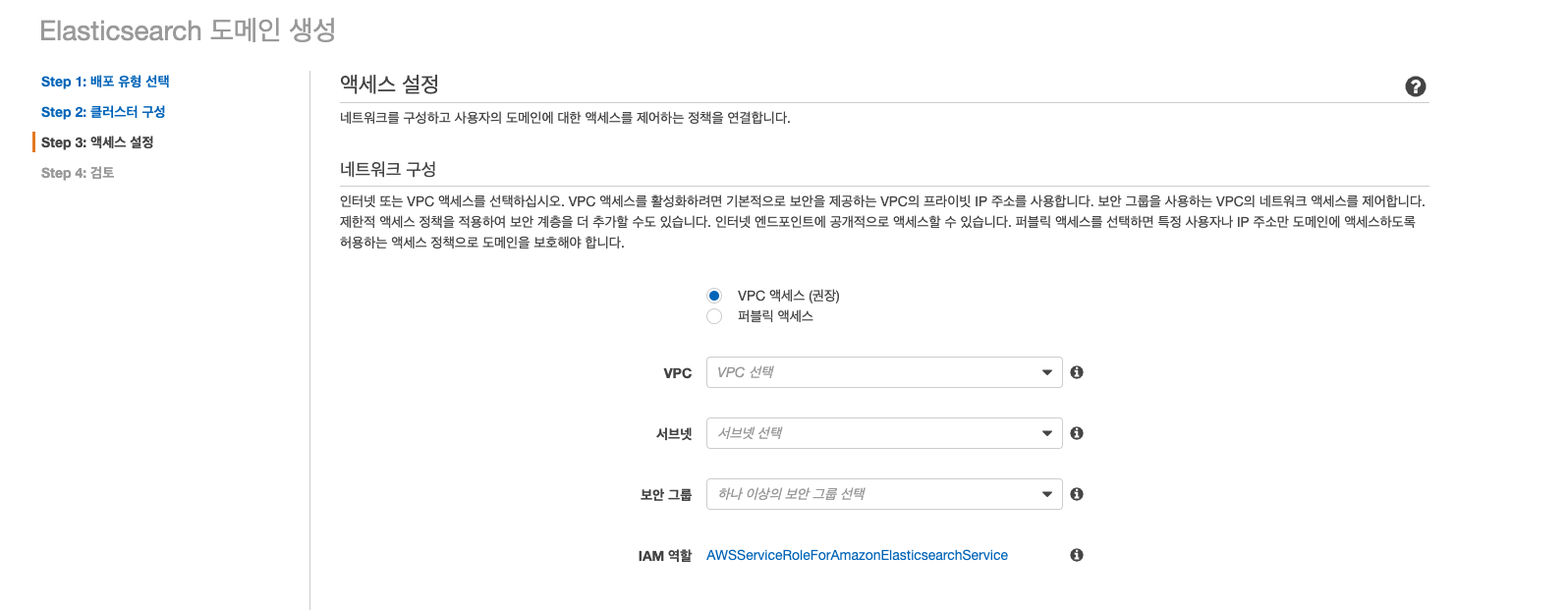
4. ES의 액세스 설정, 이건 VPC 액세스를 선택.
- 퍼블릭 액세스를 선택하지 않은 이유는 VPC 밖으로 나가는 트래픽 비용과, 보안을 생각해서 선택하지 않았음.
- SecurityGroup은 처음에 만들어둔 것을 선택하고, 서브넷은 프라이빗 서브넷을 선택한다.
- 프라이빗 서브넷은 그..NaT G/W 있는 그걸로 선택 하면 된다.
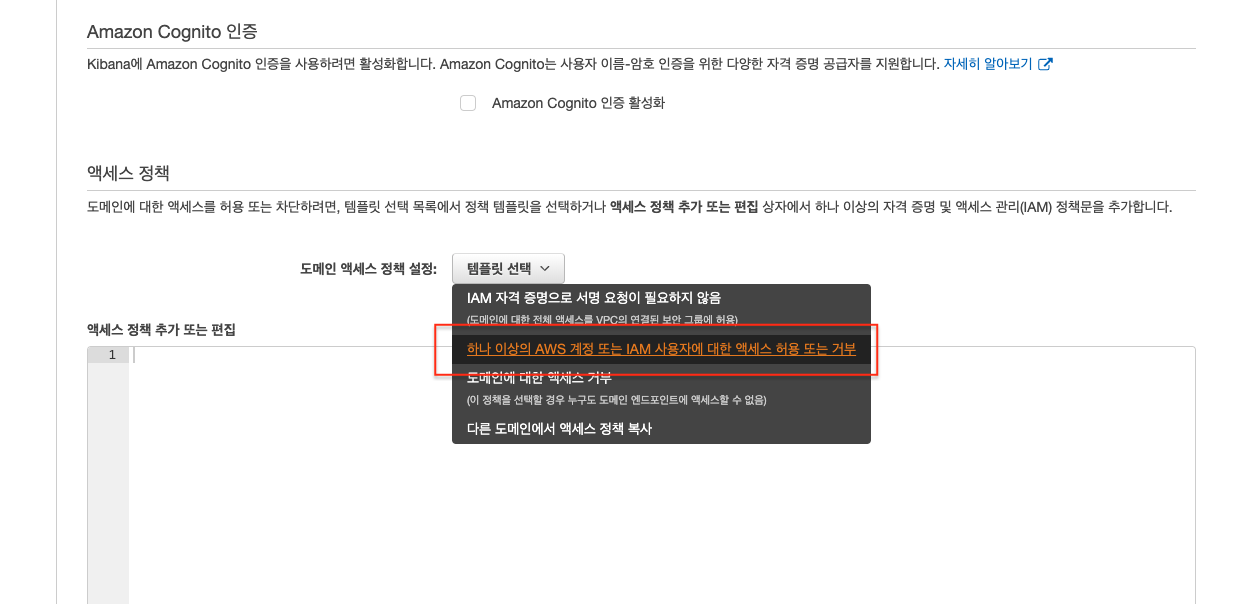
5. ES의 액세스 정책 편집
- 여러 정책중 템플릿 중 원하는 것을 선택하면 됨. 정답은 없음.
계산을 해본 것은 아닌데 일반적으로 같은 인스턴스 타입을 쓴다는 가정하에 EC2에 직접 뭔가 설치해서 사용하는 것보다
Managed Service를 사용하는게 더 비싼 것으로 알고 있다.
대신 그만큼 러닝커브가 초기 세팅 레벨에서 조금 줄어 들고, 관리포인트가 줄어든다는 것 때문에
Managed ES를 선택해서 구축 하였다.
난 뭔가 직접 처음부터 전부 다 설치하고 개발하고 싶거나 비용에 많은 압박을 받는다면 Managed Service들 보다는
직접 EC2에 구축 하면 된다.
다음 포스팅은 어플리케이션 노드의 로그 데이터들을 파싱하는 Fluentd 관련 포스팅이 될 것 같다.
다른 글을 읽고 싶다면..
- Introduce Kagent - AI agent platform for K8s
- Terraform 내장 함수 정리 — tonumber부터
- K8s GatewayAPI, Envoy Gateway
- Karpenter Disruption 정리
- Karpenter Upgrade 0.32 to 0.34
- Elasticsearch, Nori, FSCrawler를 이용한 문서 검색 엔진 구축
- K3s를 활용한 로컬 쿠버네티스 개발 환경 만들기
- Lambda Function을 활용한 AWS Application AutoScaling 자동화
- CodePipeline ECR ECS CI/CD 구현
- AWS ECS Capacity Provider 적용기
- AWS Elasticsearch, Fluentd를 활용한 로그 분석 플랫폼 구축 05
- AWS Elasticsearch, Fluentd를 활용한 로그 분석 플랫폼 구축 04
- AWS Elasticsearch, Fluentd를 활용한 로그 분석 플랫폼 구축 03
- AWS Elasticsearch, Fluentd를 활용한 로그 분석 플랫폼 구축 02
- AWS Elasticsearch, Fluentd를 활용한 로그 분석 플랫폼 구축 01
- AWS reinvent 2019 후기