
1. 시작하며
토이 프로젝트로 진행했던 검색엔진 관련 포스팅 이다. 너무 오랜만에 포스팅 하는 것 같다.
사용하는 문서들이 많아지게 되면 이걸 저장하고 찾는 행위 자체가 일이 되어 버리는 경우가 있어서
엘라스틱서치와 노리형태소분석기로 도큐먼트들을 인덱싱 해서 한글로 검색 할수 있는 시스템을 개발 해 보았다.
개발에 참고한 블로그와 URL들은 가장 하단에 기록 하였으며 사용된 기술 스택은
엘라스틱서치, 노리, FSCrawler, 도커컴포즈 정도 이고
검색 화면 같은 경우 아래 참고한 블로그에 공개된 코드를 가져와 내가 필요한 부분만 수정하였다.
본인의 깃헙 레포지토리에 코드를 공개해 놨는데 이 레포지토리의 Main 브랜치를 Clone 받은 이후에
사용하는 방법에 대해 포스팅 하겠다.
엘라스틱서치야 뭐 이젠 거의 표준이라고 말해도 과언이 아닐 정도로 많은 기업들이 활용하고 있다.
FSCrawler는 pdf, word, pptx, csv 와 같은 문서들을 주기적으로 인덱싱 해주는 오픈소스 인데
나도 모든 옵션들을 사용한 것도 아니고 디테일하게 아는 것은 아니라 아주 간단하게만 사용법에 대해 다룰 것이고
Nori는 엘라스틱 6.6부터 엘라스틱에서 공식적으로 개발하고 있는 한글 형태소 분석기 이다.
자세한 설명은 하단의 레퍼런스를 참고 하기 바란다.
특정 디렉토리에 문서(pptx,word,csv..)가 저장되면 FSCrawler는 이를 감지하고
엘라스틱서치에 인덱싱 하는데 이때 한글 형태소 분석기 Nori로 문서의 컨텐츠를 분석하여 인덱싱 한다.
여기에선 Mac 기준으로 설명하는데 Docker, Docker Compose가 설치된 모든 리눅스 환경에서 가능하다.
이것이 컨테이너화 하는 이유 이기도 하지
2. Install & Configure & Build
레포지토리에서 소스코드를 내려 받습니다.
# git clone https://github.com/wsj31013/searchCrawler.git
# cd searchCrawler
도큐먼트가 저장될 디렉토리를 생성 한다. data 디렉토리는 gitignore에 선언되어 있습니다.
# mkdir data
웹으로 사용될 Nginx 컨테이너를 빌드 합니다.
화면 수정이 필요한 사람들은 추가로 수정 후에 빌드 하면 됩니다. 본인은 퍼블리싱은 잘 몰라서
아래 참고한 블로그에서 가져온 코드를 부트스트랩 CDN을 사용하고 ajax로 데이터를 가져오는 json 필드를 수정 하였다.
# cd web
# docker build -t custom-nginx:latest .
# docker images | grep nginx
custom-nginx latest f96eb3a02bf8 3 days ago 157MB
nginx latest 9beeba249f3e 5 months ago 127MB
다시 프로젝트 홈으로 이동 합니다.
# cd ..
도커 컴포즈 파일을 확인 합니다.
# ll
total 24
-rw-r--r-- 1 wooseongjin staff 2.1K 10 20 13:40 README.md
drwxr-xr-x 4 wooseongjin staff 128B 10 20 13:40 config
drwxr-xr-x 2 wooseongjin staff 64B 10 20 13:42 data
-rw-r--r-- 1 wooseongjin staff 2.4K 10 20 13:40 docker-compose.yml
-rw-r--r-- 1 wooseongjin staff 1.7K 10 20 13:40 single-search-compose.yml
drwxr-xr-x 7 wooseongjin staff 224B 10 20 13:40 web
docker-compose.yml 은 엘라스틱서치를 멀티 노드로 구성하는 코드 이고
single-search-compose.yml 은 엘라스틱서치를 싱글 노드 구성하는 코드 입니다.
여기선 싱글 노드로 구성 합니다.
컴포즈 파일은 별거 없고 엘라스틱서치, 키바나를 7.9.2 버전으로 Pull 받아오고
엘라스틱서치 헬스체크를 기준으로 나머지 컨테이너가 기동되게 depends_on 파라미터를 사용 하였습니다.
FScrawler가 엘라스틱서치가 기동되지 않은 상태에선 Run 되지 않으므로 이렇게 구성 하였습니다.
FSCrawler 설정과 관련된 config 디렉토리를 살펴 봅니다.
# tree config
config
├── _default
│ ├── 6
│ │ ├── _settings.json
│ │ └── _settings_folder.json
│ └── 7
│ ├── _settings.json
│ └── _settings_folder.json
└── cobain
└── _settings.yaml
default/ 디렉토리는 FSCrawler에 의해 생성되는 매핑을 정의하는 파일 입니다.
현재 엘라스틱서치7.9를 사용할 것이므로 default/7/_settings.json 에 사용할 nori 형태소 분석기를 정의해둔 상태이므로
그대로 사용하면 됩니다.
cobain/ 디렉토리는 FSCrawler에서 사용할 job_name을 정의하는 디렉토리 이며
_settings.yaml에서 FSCrawler의 옵션들을 지정합니다. 정말 많은 옵션들이 있고 이 크롤러가 엘라스틱서치에 데이터들을 주기적으로
업데이트를 해야 하는 설정 값들 정도로 보면 될거 같습니다.
또한 이 job_name 디렉토리에 FSCrawler가 기동되면 _status.json 이라는 파일이 자동으로 생성되며 이는 gitignore에 정의되어 있습니다.
아마 크롤러가 저장된 문서를 주기적으로 업데이트 하는 파라미터가 update_rate 이거 일겁니다. 디폴트가 10분 일건데 저는 5분으로 지정했습니다.
FSCrawler 설정과 nori 매핑 설정도 끝냈으니 이제 컴포즈를 실행해 봅니다.
3. Run
FSCrawler가 처음 실행되면 엘라스틱서치에 위에서 설정된 job_name에 맞게 인덱스를 생성하게 되고
그 인덱스에 저장된 도큐먼트가 인덱싱 됩니다.
# docker-compose -f single-search-compose.yml up -d
Starting elasticsearch ... done
Starting searchcrawler_web_1 ... done
Starting kibana ... done
Recreating fscrawler ... done
어플리케이션의 상태를 확인해 봅니다.
# docker-compose -f single-search-compose.yml ps
Name Command State Ports
------------------------------------------------------------------------------------------------------
elasticsearch /tini -- /usr/local/bin/do ... Up (healthy) 0.0.0.0:9200->9200/tcp, 9300/tcp
fscrawler fscrawler cobain Up
kibana /usr/local/bin/dumb-init - ... Up 0.0.0.0:5601->5601/tcp
searchcrawler_web_1 nginx -g daemon off; Up 0.0.0.0:80->80/tcp
잘 된거 같네요. 이제 엘라스틱서치의 인덱스를 살펴 봐야 합니다.
# curl -X GET "localhost:9200/_cat/indices
# curl 'http://localhost:9200/cobain/_mapping'
키바나도 같이 만들었으니 키바나로 접속해서 확인해봐도 되겠죠. 사실 키바나는 이 프로젝트에
무조건 있어야 하는 컴포넌트는 아니라고 봐도 되지만 그냥 데이터 확인 용도로 같이 빌드 했습니다.
FSCrawler 튜토리얼에는 키바나에서 인덱스 패턴을 지정하고 Discover 탭에서 데이터를 볼수 있는 것까지 다 있습니다. 참고 하시고..
근데 여기서 제가 트릭을 썼습니다. 엘라스틱서치와 FSCrawler를 같이 실행하게 되면 FSCrawler에서 설정한 nori가 엘라스틱서치 플러그인으로
설치를 해둔게 아니라서 원래는 nori 없어 ㅠㅠ 라는 에러와 함께 컨테이너가 스탑 됩니다.
저는 이미 로컬에서 몇번 실행하고 nori도 설치해둔 상태라 한번에 에러없이 컴포즈가 실행 된 거죠..
이때는 엘라스틱서치에 아래 커맨드로 진입해서 노리 플러그인을 설치해 줍니다.
# docker exec -it cf7261ebb7e5 bash
여기서부턴 컨테이너 안에서 실행하는 커맨드 입니다.
[root@cf7261ebb7e5 elasticsearch]# pwd
/usr/share/elasticsearch
[root@cf7261ebb7e5 elasticsearch]# cd bin
[root@cf7261ebb7e5 bin]# ./elasticsearch-plugin install analysis-nori
[root@cf7261ebb7e5 bin]# cd ../config
[root@cf7261ebb7e5 config]# vi userdict_ko.txt
[root@cf7261ebb7e5 config]# chown elasticsearch userdict_ko.txt
userdict_ko.txt는 사용자 커스텀 사전 입니다. 사용자가 추가로 커스텀하게 원하는 한글 형태소 분석을 할수 있게
지정해주는 사용자 사전 이라고 보면 될 것 같애요.
이렇게 엘라스틱서치에서 노리 플러그인을 설치 해주고 FSCrawler를 다시 실행하면 잘 기동 될 거예요.
컴포즈에서 특정 컨테이너만 실행 시키고 싶다면 아래처럼 하면 됩니다.
# docker-compose -f single-search-compose.yml up -d fscrawler
마지막에 지정된 fscrawler를 입력 하면 됩니다. 감이 오죠?
compose 파일에서 services 아래에 작성한 컴포넌트명을 쓰면 됩니다.
4. 문서 확인 해보기
data/ 디렉토리에 검색에 사용할 문서들을 몇개 집어 넣습니다.
현재 인덱스에는 문서 카운트는 0 입니다.
# curl 'http://localhost:9200/cobain/_count'
{"count":0,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0}}
이 튜토리얼에서는 테스트에 사용될 문서 3개를 넣었습니다. FSCrawler 로그를 보면서 인덱싱이 되는지 기다립니다.
# docker logs -f 35447150c95d
05:29:30,759 INFO [f.p.e.c.f.c.BootstrapChecks] Memory [Free/Total=Percent]: HEAP [113.6mb/1.7gb=6.42%], RAM [3.2gb/7.7gb=41.37%], Swap [1023.9mb/1023.9mb=100.0%].
05:29:31,858 INFO [f.p.e.c.f.c.v.ElasticsearchClientV7] Elasticsearch Client for version 7.x connected to a node running version 7.9.2
05:29:31,962 INFO [f.p.e.c.f.FsCrawlerImpl] Starting FS crawler
05:29:31,962 INFO [f.p.e.c.f.FsCrawlerImpl] FS crawler started in watch mode. It will run unless you stop it with CTRL+C.
05:29:32,336 INFO [f.p.e.c.f.FsParserAbstract] FS crawler started for [cobain] for [/tmp/es] every [5m]
대충 10분 넘게 지난 것 같다.
# curl 'http://localhost:9200/cobain/_count'
{"count":3,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0}}
3개의 문서가 확인 된다. 형태소 분석은 잘 되었는지 키바나에서 데이터 필드들을 확인 해봅니다.
그리고 마지막으로 화면검색으로 빌드했던 웹에서 문서를 검색 해봅니다.
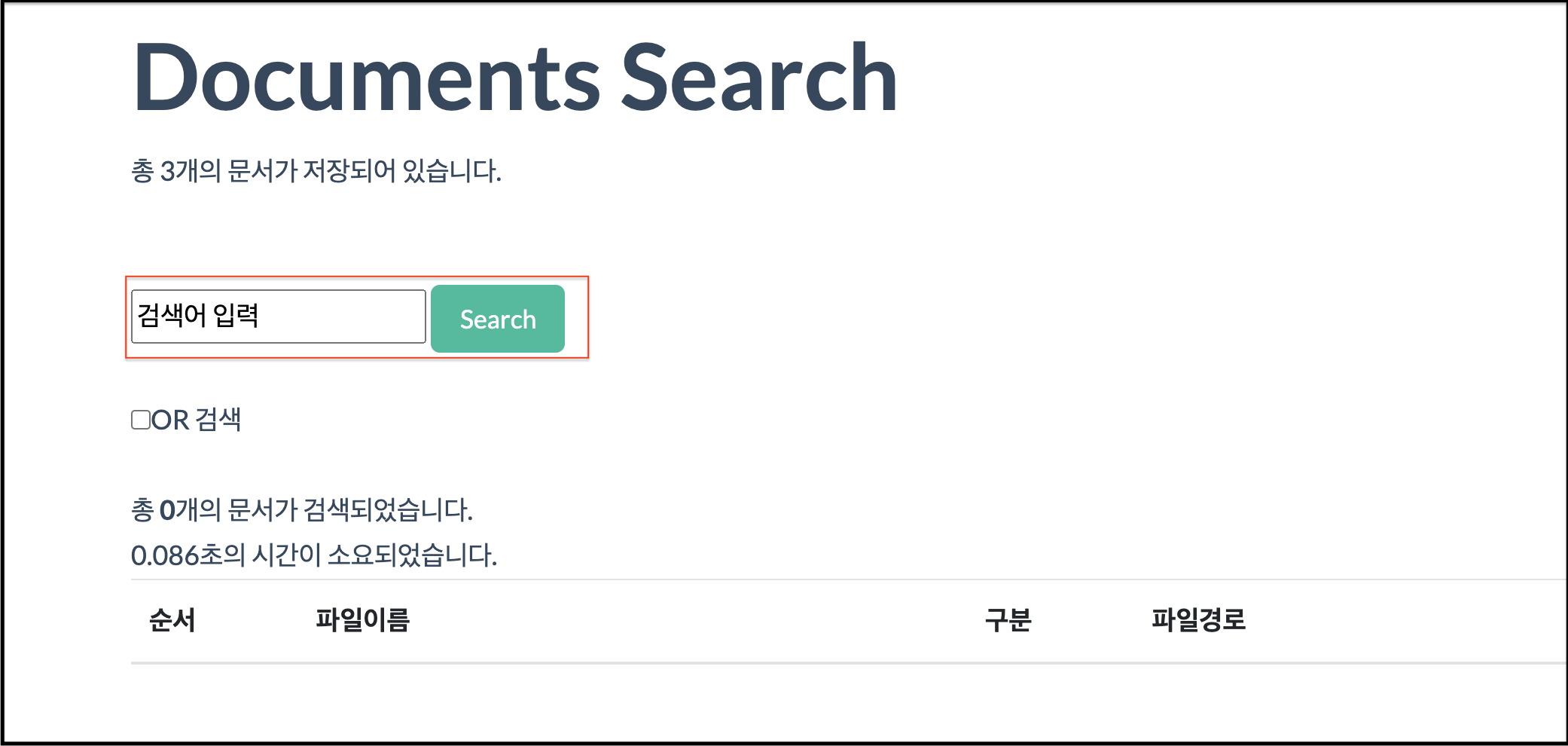
위 스크린샷 처럼 저장한 문서의 한글 검색어를 입력하면 검색이 될 거예요.
그렇습니다. 끝났습니다. 물론 이걸 프로덕션에서 바로 사용하면 안됩니다.
서치가 싱글노드 이기도 하고 좀 더 많은 케이스를 겪으며 FSCrawler의 옵션을 사용해 본 것은 아니니까요
그렇지만 일단은 완벽하진 않지만 한글이 포함된 문서를 한글로 검색하는 엘라스틱서치 기반의 검색엔진이 완성 되었습니다.
5. 이외에 Mac에서 Docker를 사용하는 소소한 팁
Mac에 설치된 Docker 엔진 버전도 올렸더니 조금 보기 편한 UI가 생긴 것을 확인 할수 있습니다.
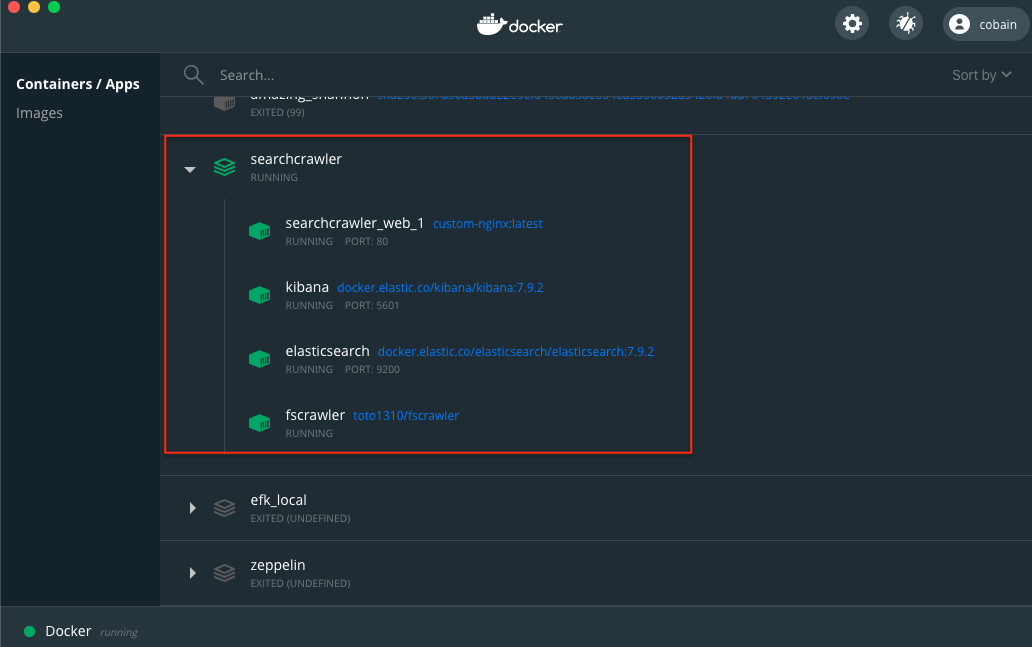
이 UI에서 vscode도 열수 있고 바로 컨테이너 쉘로 진입할 수 있는 기능들도 제공 합니다.
간혹 엘라스틱서치나 FSCrawler 컨테이너가 갑자기 죽어버리는 증상들을 몇번 겪었고 로그에 메모리 관련 에러가 남지 않아
디버깅 하는데 조금 오래 걸렸는데 이건 Mac에 설치된 Docker의 메모리 리미트값을 2GB로 설정해서
생긴 문제로서 이 값들을 본인의 메모리에 맞게 설정 하면 된다.
이걸로 검색엔진 구축 포스팅은 끝
참고한 문서
FSCrawler Github URL : FSCrawler Github
FSCrawler Documents URL : FSCrawler Readthedocs
ElasticSearch Document URL : Elasticsearch Official Home
참고한 블로그 1 : URL1
참고한 블로그 2 : URL2
Nori 형태소 분석기 : Nori