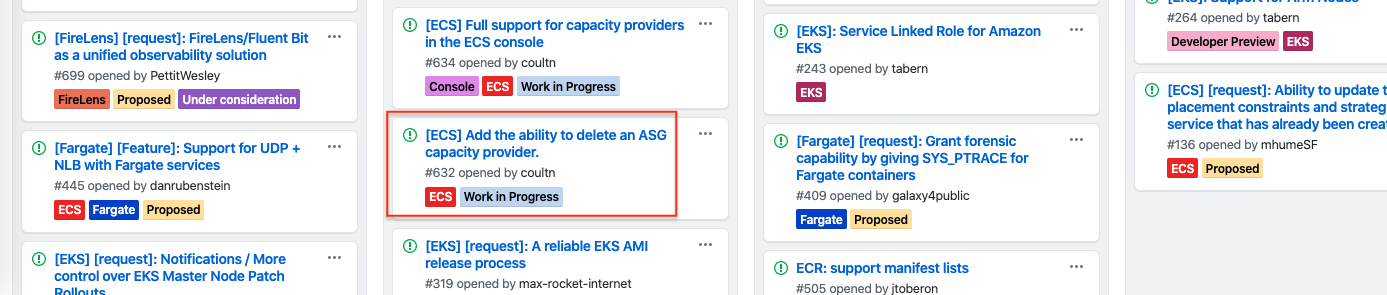
Capacity Provider를 왜 적용 해야 할까..?
컨테이너 기반의 빠른 오토스케일의 장점을 살리기 위해
ECS 클러스터의 Tasks에 필요한 인스턴스의 스케일링 자동화
기존의 EC2 오토스케일 설정할때 조금 더 빠르게 스케일링 동작을 위해 트리거 임계치를 조금 낮게 잡는 경우들이 많았었다.
근데 이렇게 되면 리소스의 낭비로 이어지고, Cost 최적화가 되지 않는 부분이 있다.
그리고 어차피 오토스케일 설정을 하더라도 인스턴스가 프로비저닝 되고 로드밸런서에서 헬스체크가 끝나서 트래픽을 유입시키는 시간이
아무리 빨라봤자 3~5분정도는 잡아야 되는데 그 약 3~5분 이라는 시간 사이에 이미 우리 고객들은 참지 않고 사이트를 나가 버린다..
이런 이유들도 있고 여러가지 이유들로 컨테이너를 도입 하게 되는데(사실 컨테이너를 쓰는 이유는 정말 많다.)
AWS ECS에서는 EC2, 서버리스(Fargate) 2가지 타입의 ECS를 제공하고 있다.
근데 이때 EC2 ECS의 경우 스케일 아웃이 될때 현재 서비스 하고 있는 EC2의 리소스(cpu, mem)가 남아 있다면
컨테이너가 Service level의 오토스케일 설정으로 스케일 아웃 되고, 이것은 설정하기 나름이긴 하지만 보통 1분 미만임.
내가 테스트 했을 때는 15~25초 사이였음. 정말 빠르지.
근데 기존 EC2에 남아 있는 리소스가 없다면? EC2를 새로 프로비저닝 해야 하는데 그럼 이것도 오토스케일 되려면 4~5분은 걸릴텐데?
그럼 나의 고객은 다 떠나 갈텐데?ㅠㅠ
그래서 짠 하고 나타난게 Capacity Provider다.ㅋㅋㅋ 지극히 주관적인 의견임. 이것은 ECS 오토스케일의 혁명이다.
ECS Principal Product Manager가 Capacity Provider에 대해 기고한 글이 있으니 한번 읽어보는게 좋다.
https://aws.amazon.com/ko/blogs/containers/deep-dive-on-amazon-ecs-cluster-auto-scaling/
위 글에서 알수 있는것은 Capacity Provider에서 설정하는 공식들이 있다는 것인데 위 글만 읽어본다면
이해가 잘 가지 않을 수 있으니 직접 테스트를 해봐야 한다.
자 그럼 ECS Capacity Provider를 구성 해보자.
이 포스팅에서 AutoScalingGroup은 "ASG", LaunchConfiguration은 "LC", Capacity Provider는 "CAS" 라고 줄여서 표현 하겠다.
1. ECS에서 사용할 ALB, Target Group
ECS에서 사용할 어플리케이션 로드밸런서와 타겟그룹을 미리 만들어 둔다.
사실 이거 다 CLI나 테라폼, CDK 같은 걸로 미리 스크립트 만들어두고 한방에 해도 되는데 처음 하는 경우
대시보드 콘솔에서 한번 작업 하는게 이해가 빠르다.
2. ECS Cluster
ECS 클러스터에서 사용할 시큐리티 그룹을 미리 하나 만들어두고 SG의 허용 소스는 당연히 1번에서 만든 ALB를 지정
딱히 공개되도 상관은 없을 것 같지만 그래도 혹시 몰라 ARN이나 ID는 안보이게 했음
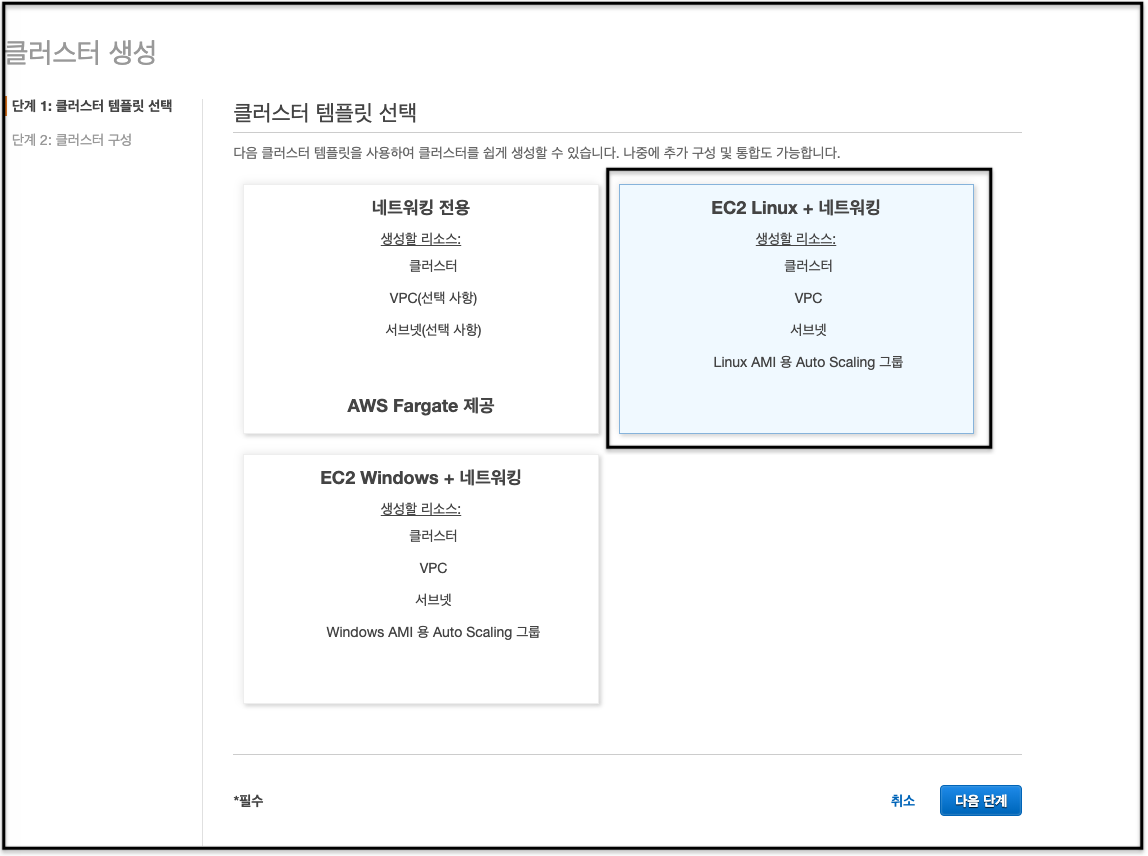
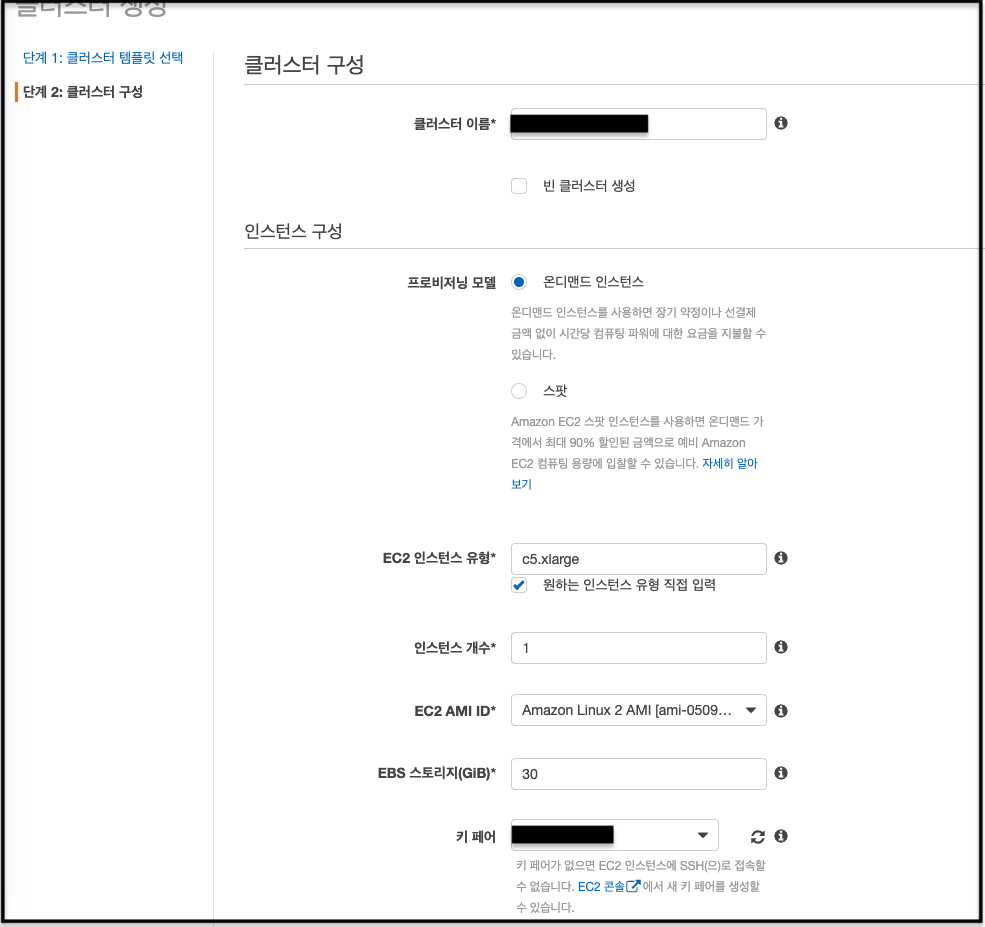

여기까지 되면 ECS에 의해 최초 인스턴스 1개가 자동 프로비저닝 되는데 아래처럼 자동 생성된 ASG를 찾아 값을 수정 한다.
이 ASG는 사용하지 않을 건데 나중에 CAS를 구성할 때 LC 복사 용도로 사용할 예정이다.

3. Tasks Definition
Tasks Definition은 어떤 이미지를 가져와 어떤 옵션으로 구동할지에 정의 하는데 별거 없어서 스크린샷은 패스
Tasks Definition까지 완료가 되었다면 이제 Capacity Provider를 작성해 볼 차례다.
여기까지 되었다면 2번에서 기본으로 생성된 ASG를 0으로 수정 했기에 인스턴스는 없는 상태이다.
4. CAS Deploy
먼저 기본으로 생성된 LC를 하나 복사해 둔다. 이것으로 CAS가 사용할 ASG를 CLI로 생성할 것이다.
굳이 이렇게 안하고 그냥 생성해도 되는데 난 복사해서 썼다.
이렇게 콘솔에서 복사할 경우 ECS Instance가 사용할 Roles가 누락 되어 ecs agent가 구동 되지 않을 수 있으므로 IAM Roles를 꼭 확인 한다.
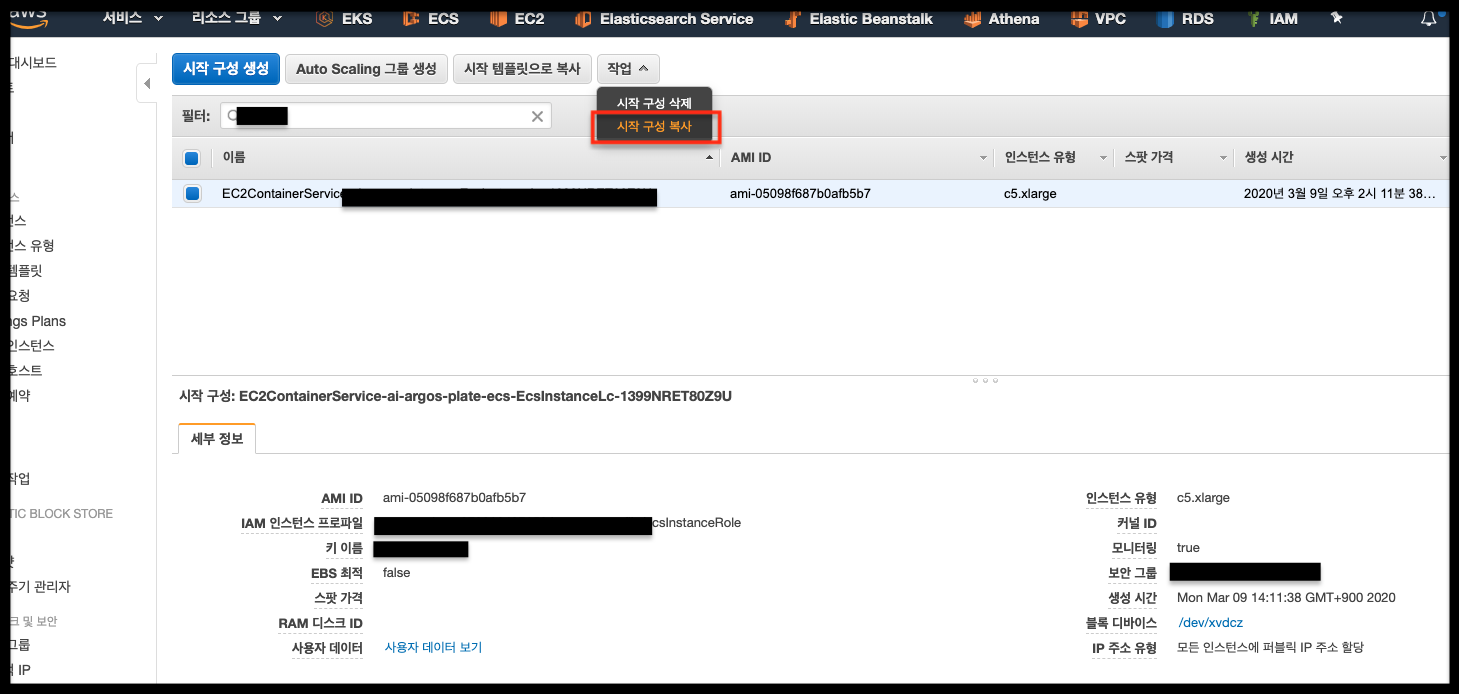
# Create ASG for CAS
# cat ecs-provider-asg01.json
{
"LaunchConfigurationName": "ecs-provider-lc01", --> 복사한 LC
"MinSize": 0,
"MaxSize": 5,
"DesiredCapacity": 0,
"DefaultCooldown": 300,
"AvailabilityZones": [
"ap-northeast-2a","ap-northeast-2c"
],
"HealthCheckType": "EC2",
"HealthCheckGracePeriod": 0,
"VPCZoneIdentifier": "subnet-11111,subnet-22222",
"TerminationPolicies": [
"DEFAULT"
],
"NewInstancesProtectedFromScaleIn": true,
"ServiceLinkedRoleARN": "arn:aws:iam::111111:role/aws-service-role/autoscaling.amazonaws.com/AWSServiceRoleForAutoScaling"
}
# aws autoscaling create-auto-scaling-group --auto-scaling-group-name ecs-provider-asg01 --cli-input-json file://ecs-provider-asg01.json --profile profile
# aws autoscaling describe-auto-scaling-groups --auto-scaling-group-name ecs-provider-asg01 --profile profile
# autoScalingGroupArn 값을 메모
# Create CAS
# cat ecs-provider01.json
{
"name": "ecs-provider05", "autoScalingGroupProvider": {
"autoScalingGroupArn": "위에서 메모한 autoScalingGroupArn 값 입력",
"managedScaling": {
"status": "ENABLED",
"targetCapacity": 100,
"minimumScalingStepSize": 1,
"maximumScalingStepSize": 100
},
"managedTerminationProtection": "ENABLED"
}
}
# aws ecs create-capacity-provider --cli-input-json file://ecs-provider01.json --profile profile
# aws ecs describe-capacity-providers --capacity-providers ecs-provider01 --profile profile
# aws ecs put-cluster-capacity-providers --cluster ecs --capacity-providers ecs-provider01 --default-capacity-provider-strategy capacityProvider=ecs-provider01,weight=1 --profile profile
# aws ecs describe-clusters --clusters ecs --profile profile
여기까지 해서 Capacity Provider가 정상적으로 적용이 됐다면 ECS “용량 공급자” 탭에서 아래와 같이 확인할 수 있다.
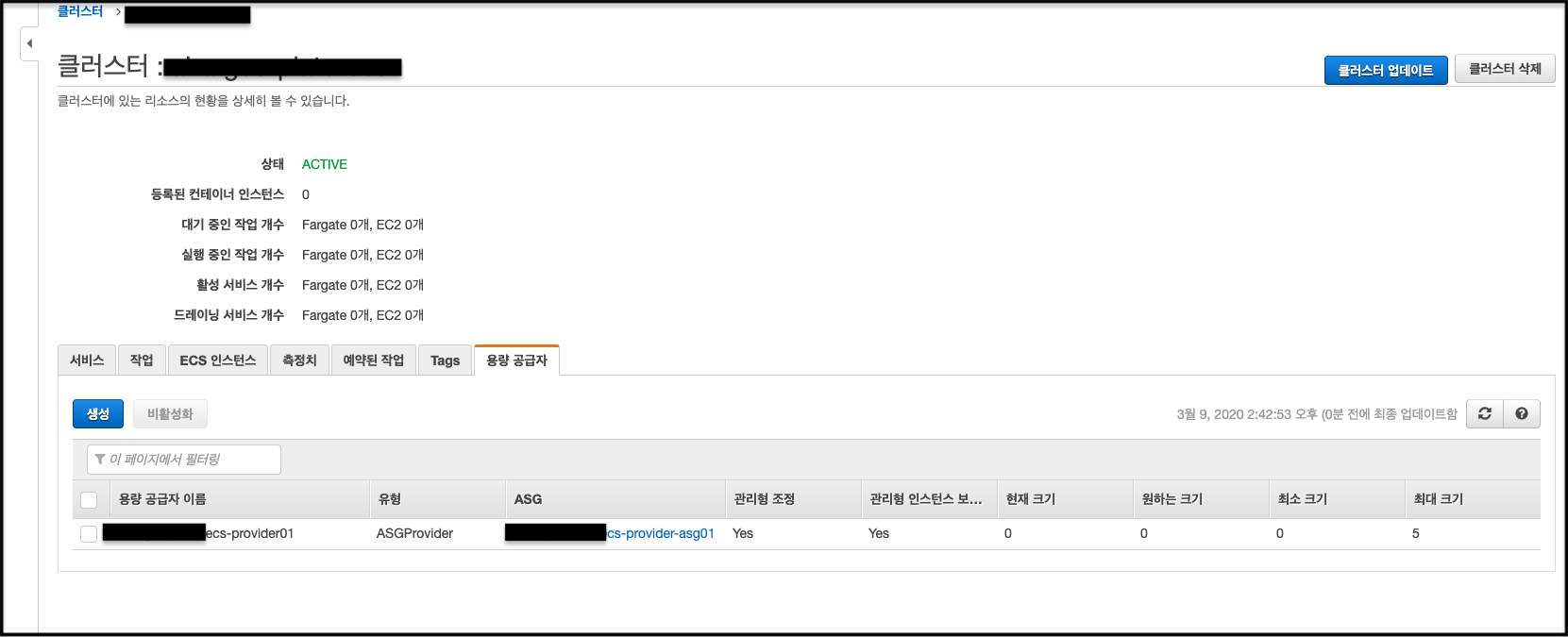
이쯤 되면 targetCapacity 이것에 대해 알아야 할 필요가 있다.
N = 기존에 존재하는 인스턴스 개수
M = Tasks가 수행하는데 필요한 전체 인스턴스 개수
targetCapacity percent = M / N * 100
targetCapacity의 value는 백분율이라서 1~100 사이의 값이 허용된다.
그리고 위 예제 처럼 100으로 설정할 경우 예비 용량 없이 모든 인스턴스가 완전히 활용 되며 M, N 즉 Tasks에 필요한 인스턴스 수 = 총 인스턴스 수 라는 얘기가 되고
만약 targetCapacity를 25로 설정 했다면 N이 M의 4배(N = 4 x M), 즉 인스턴스들의 25%가 Tasks에 사용되고 인스턴스들의 75%가 예비 용량으로 활용 된다는 얘기다.
targetCapacity의 값이 적을수록 Tasks에 사용되는 인스턴스가 적고, 예비 용량이 커지게 되어 있다.
이제 위의 ecs-provider01.json 안의 targetCapacity 값이 뭔지 이해가 됐을 거라고 생각한다.
5. Service Deploy
# Deploy Service
# aws ecs create-service --cluster ecs --service-name service --task-definition tasks --desired-count 1 \
--load-balancers targetGroupArn=arn:aws:elasticloadbalancing:ap-northeast-2:272362487653:targetgroup/,containerName=container,containerPort=8900 \
--scheduling-strategy REPLICA \
--deployment-controller '{"type": "ECS"}' \
--deployment-configuration minimumHealthyPercent=50,maximumPercent=200 \
--health-check-grace-period-seconds 120 \
--profile profile
배포가 성공적으로 되었다면 최초 2개의 인스턴스가 프로비저닝 되고, 1개의 인스턴스에서 Container가 구동 된다.
조금 더 시간이 지나면 컨테이너가 구동되지 않은 인스턴스는 자동 종료 된다.
targetCapacity:100의 값으로 결정되는 CW 메트릭에 의해 트리거 됨을 알수 있는데
CW에서 TargetTracking- 으로 시작하는 메트릭을 잘 찾아보면 CapacityProviderReservation으로 설정된 메트릭을 볼 수 있다.
CapacityProviderReservation > 100, CapacityProviderReservation < 100 일때 CAS가 트리거 됨을 확인 가능!
6. 좀 더 살펴보기, 추가 되었으면 하는 기능
Capacity Provider를 구현 하기 위해 테스트를 하다 보면 실수를 했다거나 시행착오의 과정을 거치게 될텐데
현재 2020년 3월 기준 잘못 설정된 Capacity Provider를 삭제하는 기능이 없다. 삭제하는 기능이 왜 없을까 ECS 로드맵을 보니
현재 개발 진행중 이라서 곧 추가 될 것으로 보인다.
AWS의 컨테이너 로드맵은 여기서 확인! https://github.com/aws/containers-roadmap/projects/1