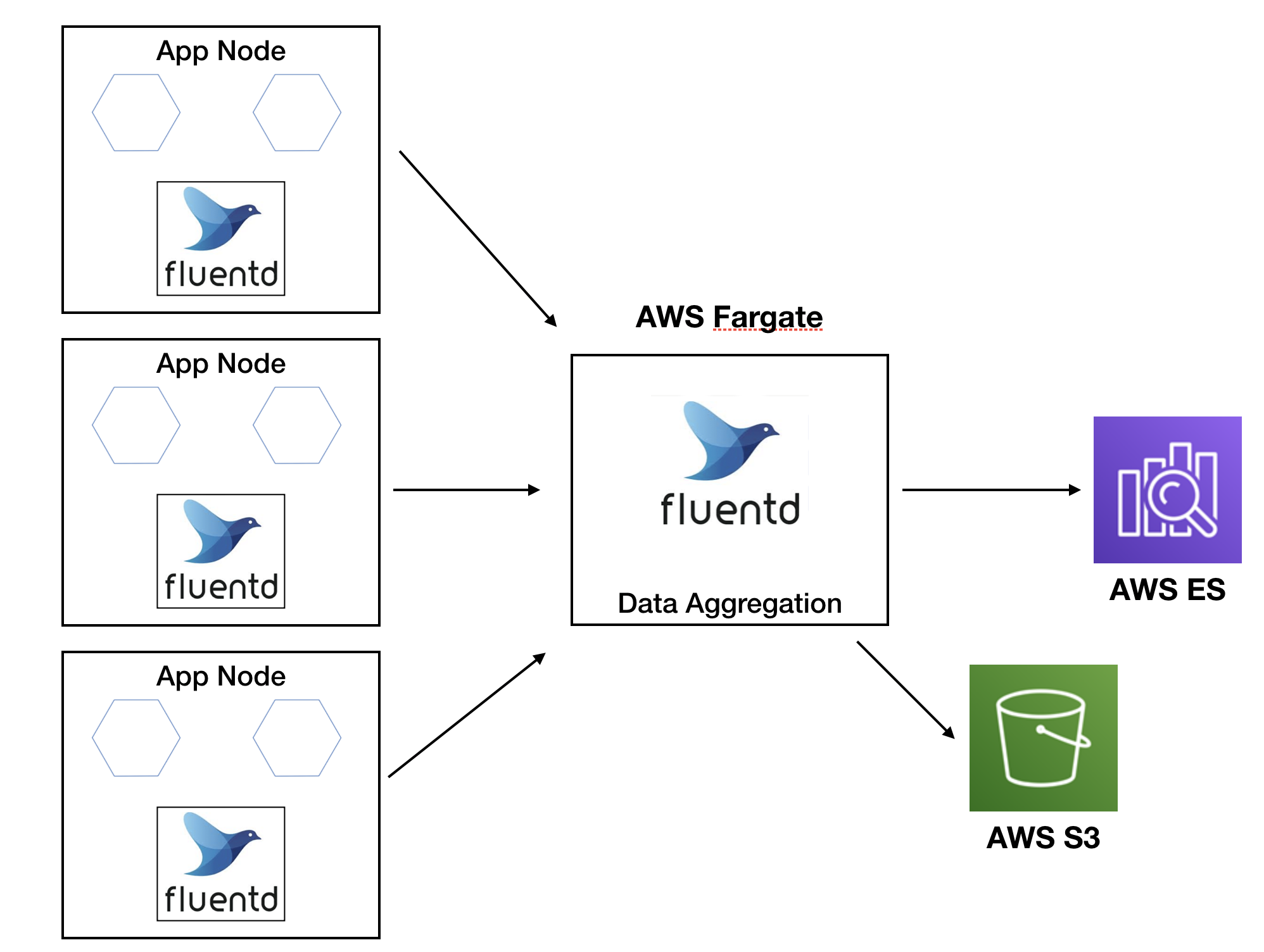
비정형 데이터인 로그들을 각각의 목적에 맞게 수집하고 분석할 수 있는 시스템이 필요했고 Elasticsearch와 Fluentd를 이용해
만들며 그 과정에 삽질 했던 것들에 대한 기록
사용된 기술 스택
- AWS Fargate
- AWS Elasticsearch
- Fluentd
위에 적고 보니 몇개 없는데 사실 가장 공들인게 로그 데이터 파싱과 Elasticsearch Mapping 설계 였다.
Fargate를 이용한 컨테이너화, VPC 네트워크 플로우등을 설계 하는 것은 그리 오래 걸리지 않았다.
작업을 하다 보니 어플리케이션 로그들의 포맷이 달랐고 Sleuth, Logback등을 따로 찾아봐야 해서 조금 더 오래 걸렸다.
그리고 중간에 Data Transformation 역할로 AWS Kinesis를 쓸까 하다가 AWS ES 7.x와 호환이 안되는 문제로
Kinesis는 제외하게 되었고, Kafka도 잠깐 고려했는데 Fluentd로 Aggregator, Buffer 로서의 역할이 충분하다고
판단되어 어플리케이션 부터 Elasticsearch로 Dump 하기 전까지 Fluentd로 통일했다.
아 그리고 Fluentd Bit로도 어플리케이션 노드쪽에 심을 수 있는데, 오히려 그게 더 경량화 되어 좋을 것 같았다.
근데 현재 내가 일하는 곳 특성상 Fluentd Bit를 심을 수 있는 환경이 아니어서 일단은 Fluentd로 진행 하였다.
포스팅들은 대략 아래의 순서대로 진행할 예정이다.
1. AWS Elasticsearch 구성
2. App node 데이터 파싱
3. Aggregator Fluentd 구성 및 컨테이너화
4. Cloudformation을 이용한 Fargate 배포